Web scraping seguro: técnicas éticas para extraer datos en 2025
14 mar 2025

l web scraping es una técnica poderosa para obtener datos de páginas web: precios, listados, contenidos públicos o indicadores para investigación. Pero en 2026 ya no basta con saber extraer información: hay que hacerlo de forma ética, legal y sostenible.
Un scraping mal planteado puede causar bloqueos, demandas o problemas de cumplimiento (GDPR/LOPD), mientras que un enfoque responsable abre puertas a análisis sólidos, automatizaciones y proyectos de datos respetuosos con los propietarios del contenido.
En este artículo aprenderás qué es el web scraping seguro, cuándo usarlo, qué prácticas técnicas aplicar y qué aspectos legales debes tener siempre en cuenta. También verás alternativas legales (APIs, acuerdos de datos) y una checklist práctica para empezar con seguridad.
Dominar scraping ético es una habilidad clave si trabajas en data engineering, BI o product analytics. En nuestros programas integramos prácticas reales y gobernanza de datos para que puedas automatizar sin riesgo.
¿Qué es el web scraping?
¿Qué es el web scraping seguro?
El web scraping seguro se refiere a la extracción automatizada de datos de páginas públicas respetando normas, límites y la seguridad técnica del servidor. No se trata solo de «cómo» recoger HTML, sino de cómo hacerlo sin dañar la infraestructura ajena, sin violar términos legales y sin poner en riesgo datos personales.
Elementos que definen un scraping seguro:
Transparencia técnica: respetar
robots.txtyrobotsmeta, usar unUser-Agentidentificable y contactar al propietario si es necesario.Tasa de peticiones responsable: implementar rate limiting y backoff exponencial para evitar sobrecargar servidores.
Respeto a la privacidad: no recolectar datos personales sensibles sin bases legales claras (consentimiento, interés legítimo).
Alternativas previas: preferir APIs oficiales, feeds o acuerdos de datos antes de scrapear.
Gestión ética de la información: atribuir origen, respetar copyright y no redistribuir datos restringidos.
Scraping seguro = técnico + legal + ético. Si una sola de estas patas falla, el proyecto queda en riesgo.
¿Cómo funciona el web scraping seguro?
Hay que reconocer que, a pesar de que el web scraping puede ser de gran utilidad, lo cierto es que también puede ser empleada para actividades poco éticas o incluso ilegales.
Debido a la forma en la que trabaja, su uso presenta algunos desafíos importantes a tener en consideración.
Es por ello que, dentro del Big Data, existe una distinción con respecto al uso del web scraping seguro.
En este caso, se trata de emplear esta herramienta para la recolección de datos que no atenten contra la privacidad y seguridad de los sitios web de los que son extraídos.
Así que, al emplear el web scraping de forma segura, se garantiza que se cumplan con los términos de seguridad y se tiene que asegurar que el uso de la información no comprometerá la protección o confidencialidad de los mismos.
Además, esta nueva forma de trabajar con el raspado web también permite evitar la sobrecarga de los servidores. De esa manera, se evita que el desarrollo de este tipo de actividad pueda afectar el rendimiento del sitio web en cuestión.
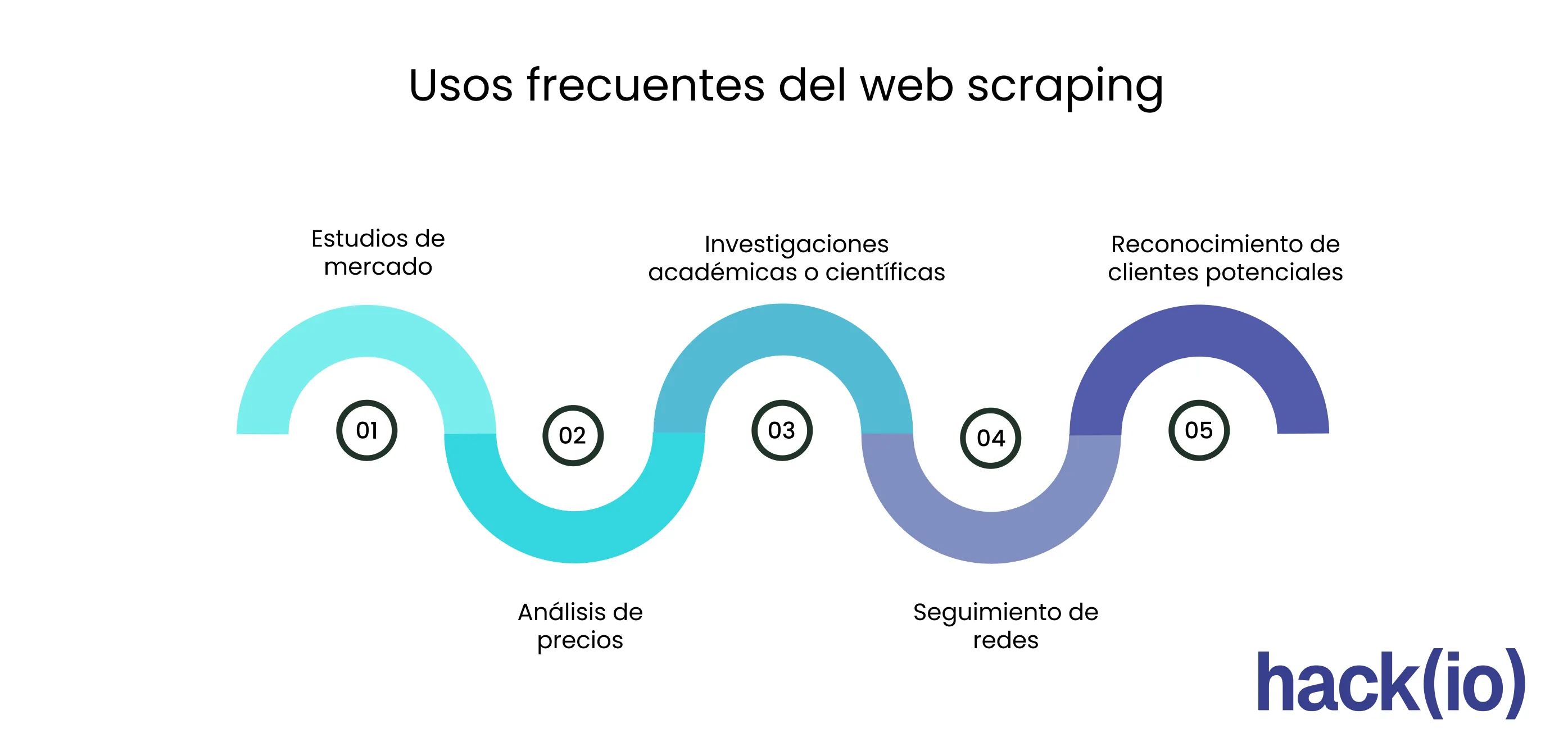
Casos de uso legítimos y beneficios del web scraping
El web scraping no tiene por qué ser una práctica negativa.
Cuando se aplica con responsabilidad, puede convertirse en una herramienta poderosa para análisis, investigación y automatización de tareas.
A continuación, te mostramos algunos usos legítimos y frecuentes
Caso de uso | Descripción | Ejemplo |
|---|---|---|
Análisis de mercado y precios | Recopilar información pública sobre productos o servicios para detectar tendencias. | Comparar precios de tiendas online o tarifas de vuelos. |
Monitorización SEO | Extraer datos públicos de resultados de búsqueda o backlinks. | Auditar posiciones, enlaces y metadatos. |
Investigación académica o social | Recoger información pública de foros, redes o portales institucionales. | Analizar opiniones o políticas públicas. |
Inteligencia empresarial (Business Intelligence) | Integrar datos externos en dashboards o informes. | Cruce de datos públicos con indicadores internos. |
Actualización de bases de datos | Mantener directorios, catálogos o listados actualizados con fuentes abiertas. | Listados de empresas, eventos o APIs públicas. |
Consejo Tech School: el web scraping puede ayudarte a convertir datos dispersos en conocimiento útil, siempre que respetes la legalidad y la infraestructura de origen.
Técnicas seguras y checklist técnico para un scraping ético
Para hacer scraping responsable no basta con saber programar un crawler: hay que diseñarlo con buenas prácticas técnicas que garanticen seguridad, respeto y eficiencia.
Aquí tienes una checklist esencial para 2026 👇
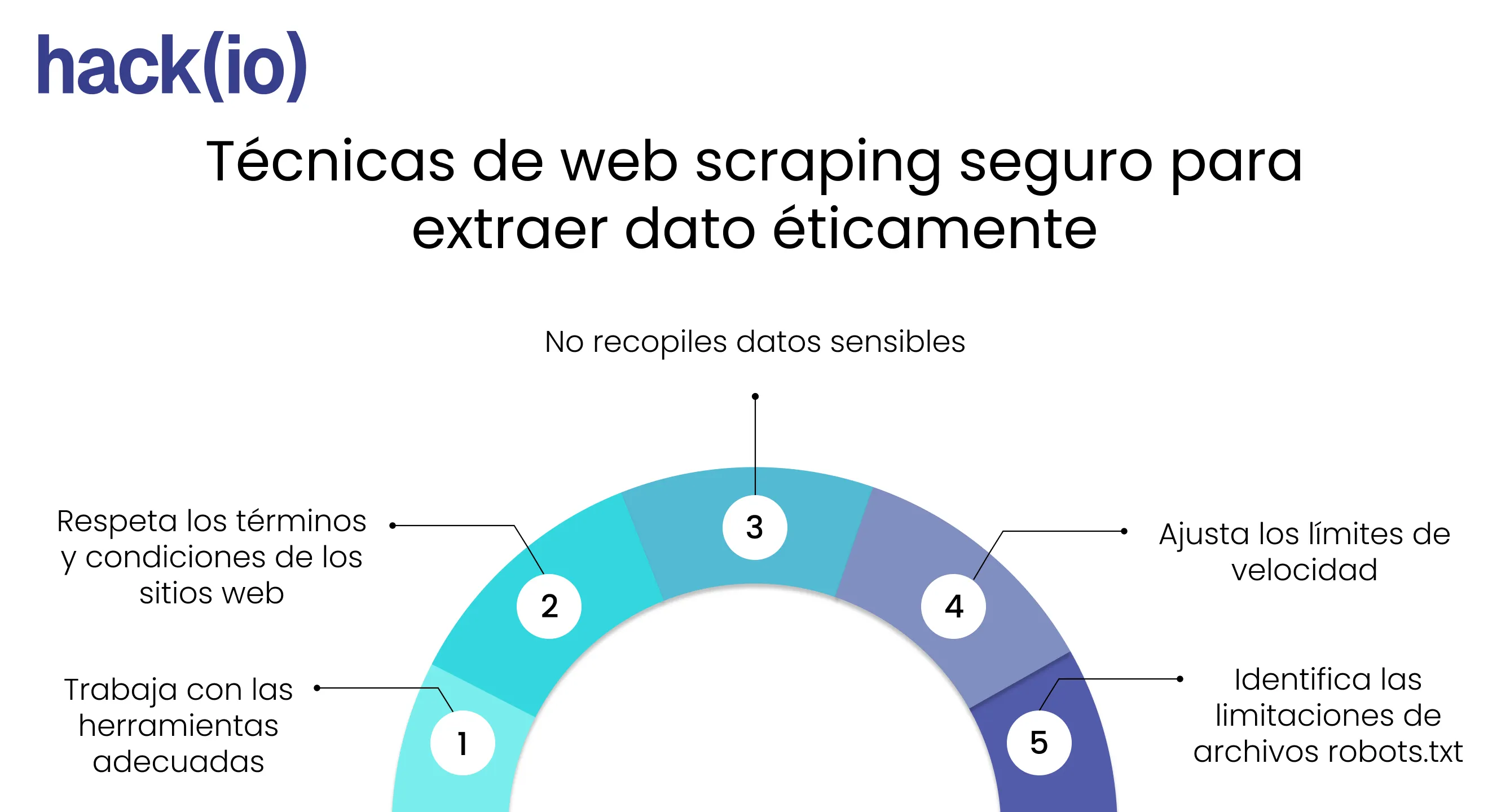
✅ Checklist técnico para web scraping seguro
Revisa el archivo
robots.txt
Este archivo indica qué partes del sitio pueden ser rastreadas.Ejemplo:
https://example.com/robots.txtUsa un
User-Agentidentificable
Evita impersonar navegadores o bots ajenos.Aplica límites de velocidad (rate limiting)
Introduce pausas entre peticiones para no sobrecargar servidores.Respeta cabeceras y códigos HTTP
403 → acceso prohibido
429 → demasiadas peticiones (debes frenar o espaciar las solicitudes)
Evita extraer datos personales
No recopiles información que permita identificar a personas (emails, teléfonos, perfiles) sin consentimiento o base legal.No evadas medidas de seguridad
Nada de saltarse captchas, autenticaciones ni cookies protegidas.
Si necesitas esos datos, busca una API o contacto oficial.Usa almacenamiento temporal y anonimización
Guarda solo los datos necesarios y elimina los identificadores personales.Automatiza con herramientas seguras
Frameworks como Scrapy, BeautifulSoup, Playwright o Selenium pueden ayudarte a procesar información respetando tiempos y cabeceras.Prefiere APIs públicas o endpoints documentados
Antes de scrapear, verifica si existe una API disponible o acuerdos de uso de datos.Monitoriza tu crawler
Controla errores, tiempos de respuesta y bloqueos. Un scraper bien diseñado debe ser sostenible y predecible.
Aspectos legales y éticos del web scraping
El web scraping no solo es una cuestión técnica: también implica responsabilidad legal y ética.
En Europa y Latinoamérica, los datos están protegidos por normativas como el RGPD (Reglamento General de Protección de Datos) y las leyes de propiedad intelectual y de servicios digitales.
Por eso, antes de automatizar la extracción de información, debes tener muy claro qué puedes y qué no puedes hacer.
Cuándo el web scraping es legal
El scraping es generalmente legal cuando cumple con estas condiciones:
Los datos son públicos y no personales.
Es decir, se encuentran visibles sin necesidad de iniciar sesión ni acceder a información privada.
Ejemplo: precios, listados de productos o estadísticas oficiales.No vulnera los Términos de Uso del sitio.
Si un portal prohíbe expresamente el scraping, es preferible pedir autorización o usar su API oficial.No afecta al rendimiento del servidor.
Tus bots no deben generar una carga excesiva ni bloquear la disponibilidad del sitio.No copias ni redistribuyes contenido protegido.
Textos, imágenes o bases de datos con copyright solo pueden reutilizarse si existe permiso o licencia compatible.Respetas la privacidad y anonimato.
Nunca recojas datos personales (como emails, teléfonos o nombres completos) sin una base legal clara o consentimiento explícito.
Cuándo el web scraping es ilegal o arriesgado
Acceder a zonas restringidas o protegidas por contraseña.
Evadir mecanismos de autenticación o CAPTCHA.
Recolectar datos personales sin consentimiento.
Extraer contenido masivo con fines comerciales sin permiso.
Usar los datos obtenidos para suplantar identidad, enviar spam o dañar reputaciones.
Recuerda: aunque técnicamente sea posible, no todo lo que se puede hacer es ético o legal.
Buenas prácticas éticas
Informa siempre el propósito de la recolección si compartes o publicas resultados.
Usa los datos para análisis, investigación o formación, no para replicar o competir directamente con el sitio fuente.
Da crédito o enlace al origen de los datos cuando sea posible.
Mantén transparencia en tus procesos: documenta el método, las fuentes y las fechas de extracción.
Alternativas legales y herramientas recomendadas para extraer datos
Antes de recurrir al scraping, existen opciones más seguras y legales para obtener información: APIs públicas, open data y herramientas profesionales que permiten acceder a datos de forma controlada y ética.
Fuente / Herramienta | Tipo de acceso | Uso recomendado |
|---|---|---|
APIs oficiales (Google, Twitter, YouTube) | Gratuito o con registro | Acceso directo a datos actualizados y legales. |
Portales Open Data (Data.gov, Datos.gob.es, Kaggle) | Público y libre | Datos abiertos de gobiernos o instituciones. |
Marketplaces (RapidAPI, Azure Marketplace) | De pago o suscripción | Datos empresariales con licencias seguras. |
Scrapy / BeautifulSoup (Python) | Código abierto | Extracción controlada de datos públicos. |
Apify / Octoparse | SaaS no-code | Scraping ético con límites automáticos y APIs integradas. |
Conclusión
El web scraping seguro es una habilidad clave para cualquier profesional de datos o desarrollo web.
Cuando se aplica correctamente, te permite convertir la información pública en conocimiento útil, optimizar procesos y generar oportunidades reales en el mundo digital.
Aprender a hacerlo bien significa entender tanto el lado técnico como el ético.
Si quieres dominar ambas perspectivas, fórmate con nosotros.
🚀 En ThePower Tech School y el programa Rock The Code y el Programa Data Analytics aprenderás a trabajar con datos, APIs y automatización desde la práctica, con un enfoque seguro y profesional.
Preguntas frecuentes sobre web scraping seguro
¿Qué es el web scraping seguro?
Es la práctica de extraer datos públicos de forma automatizada respetando las normas técnicas, legales y éticas del sitio web de origen.
¿Es legal hacer web scraping?
Sí, siempre que los datos sean públicos, no personales y no se violen los términos de uso ni los derechos de autor del sitio.
¿Qué riesgos tiene hacer scraping sin control?
Puedes ser bloqueado, sancionado o enfrentarte a problemas legales por sobrecargar servidores o recolectar datos personales sin permiso.
¿Qué alternativas existen al scraping?
APIs oficiales, portales de open data y data marketplaces con licencias claras son opciones más seguras y sostenibles.
¿Dónde aprender web scraping ético?
En ThePower Tech School, dentro del programa Rock The Code, aprenderás scraping, APIs y automatización de datos con responsabilidad y visión profesional.
Nuestro artículos más leídos


Aprende cómo funcionan empresas como Netflix ó Spotify. Qué es SAAS (Software as a Service). ¡Descubre las ventajas y desventajas!
VER ARTÍCULO

Es un lenguaje donde tu como programador le das instrucciones al ordenador para que las cumpla en un determinado momento.
VER ARTÍCULO

¿Tienes un iPhone o Mac? Aprende cómo funciona Airdrop y cómo enviar archivos entre dispositivos Apple de forma rápida y sin cables.
VER ARTÍCULO

Comparativa 2026: diferencias reales entre iPhone y Android en rendimiento, cámaras, IA, seguridad, ecosistema y precio. Descubre cuál encaja contigo.
VER ARTÍCULO

¿Confundido con el término “localhost”? Aprende qué significa, cómo funciona en programación y por qué es clave para pruebas en tu ordenador.
VER ARTÍCULO

Domina el diseño de layout para crear la mejor experiencia. Organiza elementos con maestría y cautiva a tu audiencia.
VER ARTÍCULO

